CONNECTION + ENGINE = iceberg. External tables → SOURCE (read) / SINK (write).
| Concept | When / what (internal vs external) | Key SQL |
|---|---|---|
CONNECTION | Internal — save Iceberg catalog + object storage config for ENGINE = iceberg. See Internal Iceberg tables. | CREATE CONNECTION + SET iceberg_engine_connection = 'schema.conn' |
SINK | External — write streaming results to an external Iceberg table. See Deliver to external Iceberg. | CREATE SINK ... WITH (connector = 'iceberg', ...) |
SOURCE | External — read an external Iceberg table into RisingWave. See Ingest from external Iceberg. | CREATE SOURCE ... WITH (connector = 'iceberg', ...) |
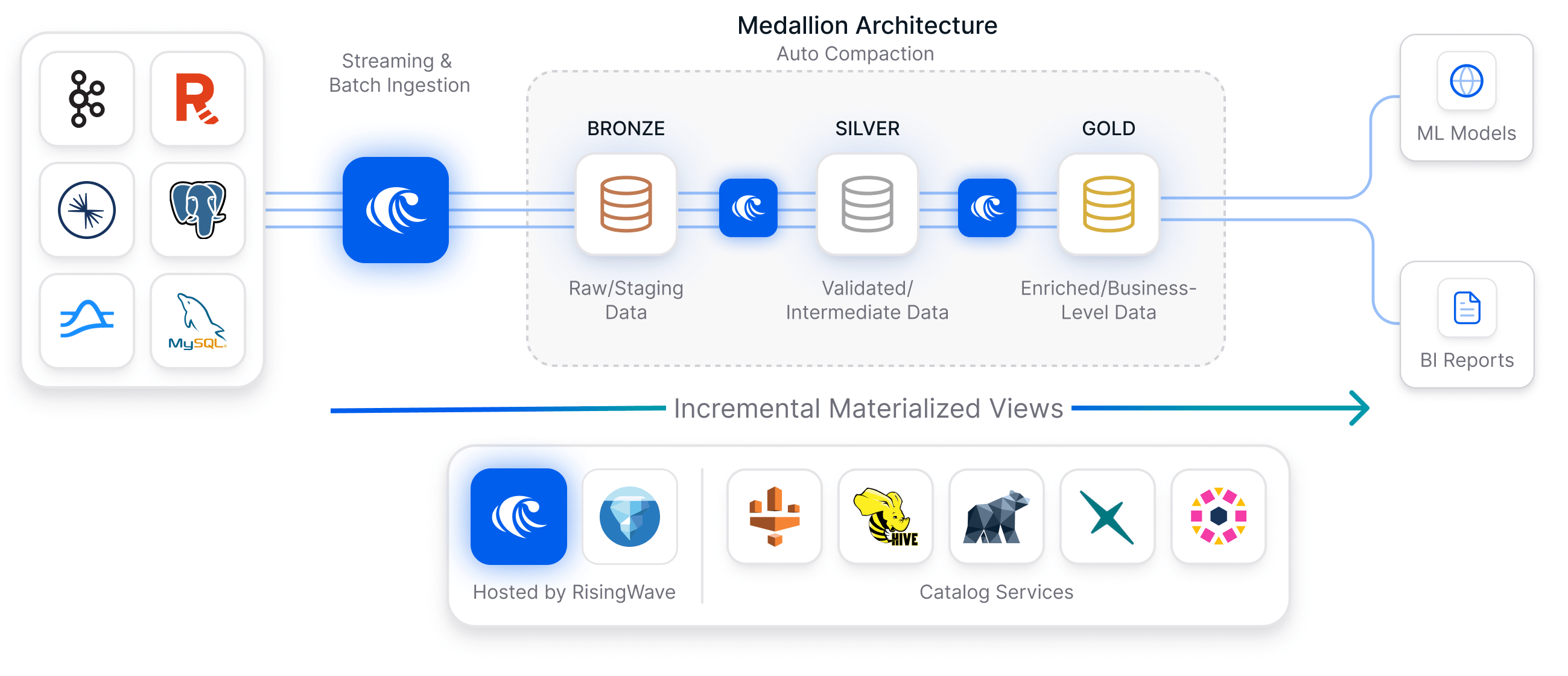
RisingWave in a medallion architecture
RisingWave bridges real-time streaming systems with Iceberg-based data lakes. It functions as the continuous ingestion, transformation, and maintenance service within a Medallion architecture, ensuring that data seamlessly transitions from raw sources to optimized, query-ready Iceberg tables through incremental computation and cascading materialized views.