- Ingestion can be implemented as ETL or ELT pipelines that continuously write data into Iceberg tables.
- Transformation is powered by RisingWave’s incremental materialized views, enabling efficient, cascading updates across multiple layers of derived data.
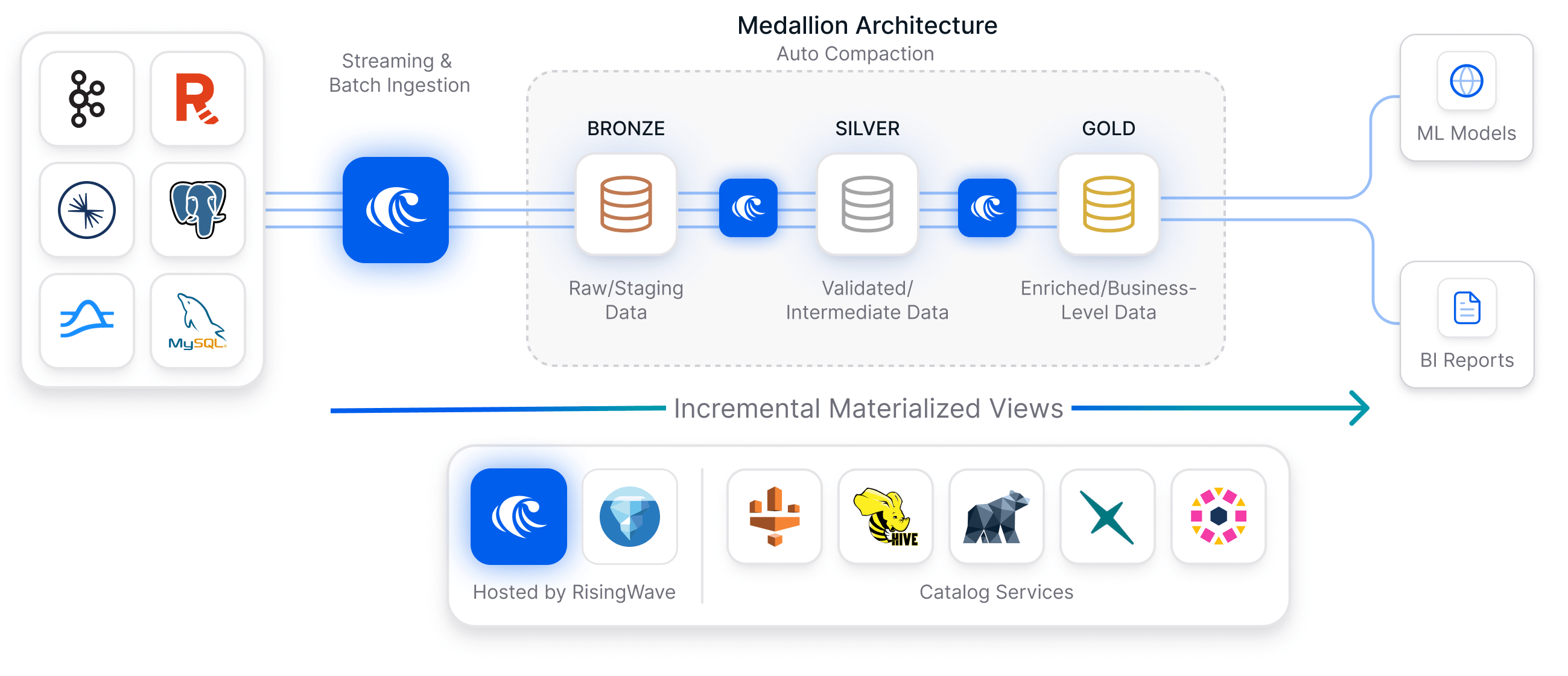
- Use internal Iceberg tables as the Bronze layer for raw data storage.
- Use materialized views as the Silver layer to filter and transform data.
- Use cascading materialized views (built on top of the Silver layer MVs) as the Gold layer to aggregate and enrich data for analytics.
Hosted catalog services
RisingWave provides two hosted catalog options for managing Iceberg metadata, schema versions, and table state:- Built-in catalog: Uses RisingWave’s metastore database as a JDBC-compliant catalog. Requires PostgreSQL or MySQL as the metastore backend (SQLite is not supported). See Built-in catalog.
- Self-hosted REST catalog: You can deploy a standalone REST catalog service like Lakekeeper.
External query engine access
Both options allow external Iceberg engines to read and write RisingWave-managed tables using standard Iceberg protocols. If you prefer to use an existing metadata system, RisingWave also supports external catalogs such as AWS Glue, Hive Metastore, or Nessie. See Catalog configuration for details.Compaction service
RisingWave provides a managed compaction service that helps maintain table health by performing compaction and snapshot expiration.- Compaction: Merges small data files into larger, optimized files to improve read performance.
- Snapshot Expiration: Removes old, unneeded snapshots and their associated data files to reclaim storage space.
VACUUM command. Using RisingWave’s service is optional, and you can also connect an external compactor from providers like Amazon EMR, or use a self-hosted Spark job.
Automatic Iceberg maintenance requires a dedicated compactor node in your cluster. Before enabling
enable_compaction = true, see Deploy a dedicated Iceberg compactor for deployment and sizing instructions.Catalog and compaction summary
| Component | RisingWave Native Options | Alternative Options | Description |
|---|---|---|---|
| Catalog service | Built-in catalog (JDBC) or a self-hosted REST catalog (Lakekeeper) | Glue, Hive, Nessie, or custom REST catalogs | Stores metadata and schema information |
| Compaction service | RisingWave’s built-in compaction service | External services (Aamazon EMR) or self-hosted Spark | Merges small files and expires old snapshots |