High-level comparison
To quickly grasp the differences, the following table illustrates how these four objects vary in terms of storage, queryability, and typical use cases.| Object | Persist Data? | Queryable? | When To Use? |
|---|---|---|---|
| Table | ✅ | ✅ | Persisting data, querying, serving as input for MVs or Sinks |
| Source | ❌ | Depends on the connector (see below) | Data ingress, ad-hoc exploration, building Tables or MVs |
| MV | ✅ | ✅ | Real-time aggregation, transformation, analysis |
| Sink | ❌ | ❌ | Writing results back to Kafka, databases, or object storage |
Connector support matrix
Users often ask: “Can I query this Source directly? Do I need to create a Table for CDC connectors?” The matrix below shows which connectors support direct Source queries and which require creating a Table.| Connector Type | Directly Query Source? | Primary Key Required? |
|---|---|---|
| Kafka / Pulsar / Kinesis / NATS / MQTT / PubSub | ✅ | ❌ |
| S3 / GCS / Azure Blob | ✅ | ❌ |
| PostgreSQL CDC | ❌ | ✅ |
| MySQL CDC | ❌ | ✅ |
| SQL Server CDC | ❌ | ✅ |
| MongoDB CDC | ❌ | ✅ |
| Iceberg | ✅ | ❌ (Unless declared for writes) |
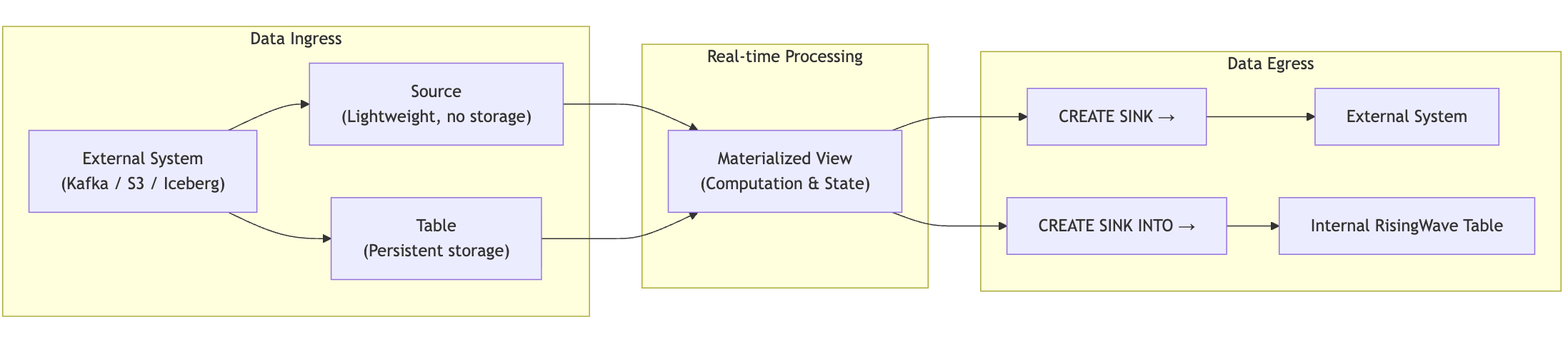
Table and Source
Table: the foundation of storage in RisingWave
A Table in RisingWave is a persistent data object that stores a collection of rows, behaving much like a traditional database table. It can store, query, and update data. There are two ways to use a Table: First, as an internal table where users manually insert data.Source: a lightweight ingress definition
Unlike a Table, a Source only defines how to connect to an external system and does not store any data within RisingWave. For Sources like Kafka, S3, and Iceberg, you can execute SELECT queries directly:CDC always requires creating a table
What makes a CDC (Change Data Capture) stream special is that it includes updates and deletes. RisingWave must rely on a Table to process these events correctly. If a user executesUPDATE users SET name='Bob' WHERE id=1 in PostgreSQL, RisingWave needs to know which row to update. Only a Table, which stores the data’s state and has a primary key, can support this semantic. Furthermore, a CDC stream is a continuous log of changes. If it were just a Source, consistency could not be restored after a task interruption. A Table, on the other hand, can resume from the last checkpoint thanks to its persistence and offset tracking. Finally, a single database transaction might update multiple tables. RisingWave relies on Tables to correctly apply transactional boundaries.
Therefore, for CDC, you must create a table. You can either create a CDC table directly or create a Source first and then derive a Table from it.
Shared Sources and consistency
For PostgreSQL CDC, MySQL CDC, and SQL Server CDC scenarios, RisingWave provides a shared source mechanism. A user can create a single CDC Source and then derive multiple Tables from it: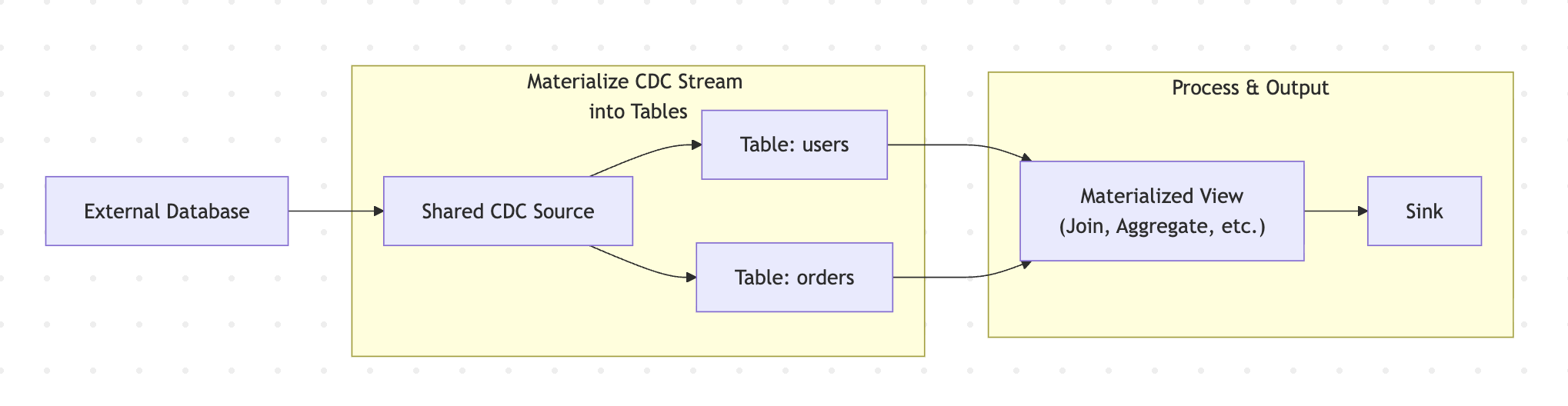
Materialized View
The Materialized View (MV) is the core of real-time computation in RisingWave. It is defined by a SQL query, and the system automatically maintains the result table, refreshing it in real-time as the underlying data updates.Sink
A sink is the egress point of RisingWave, used to write data to external systems. The input for a sink can be:- An existing object such as a source, table, or materialized view, which is defined by the FROM clause in a
CREATE SINKstatement. - A query, which is defined by
CREATE SINK AS SELECT <select_query>syntax.
CREATE SINK INTO command. A common use case for this is to union multiple sources and write them into a single table.
Summary
Here’s a quick recap of the four core objects in RisingWave:- Table: The storage layer. Mandatory for CDC scenarios. Stores the current state of data.
- Source: A lightweight ingress point. Non-CDC Sources can be queried directly, while CDC Sources must be materialized into a Table.
- MV: The result table of real-time computation. Recommended as the upstream for a Sink.
- Sink: The output layer. Supports three creation syntaxes:
FROM,AS SELECT, andINTO.