| Node Type | Brief Description | Detailed Description |
|---|---|---|
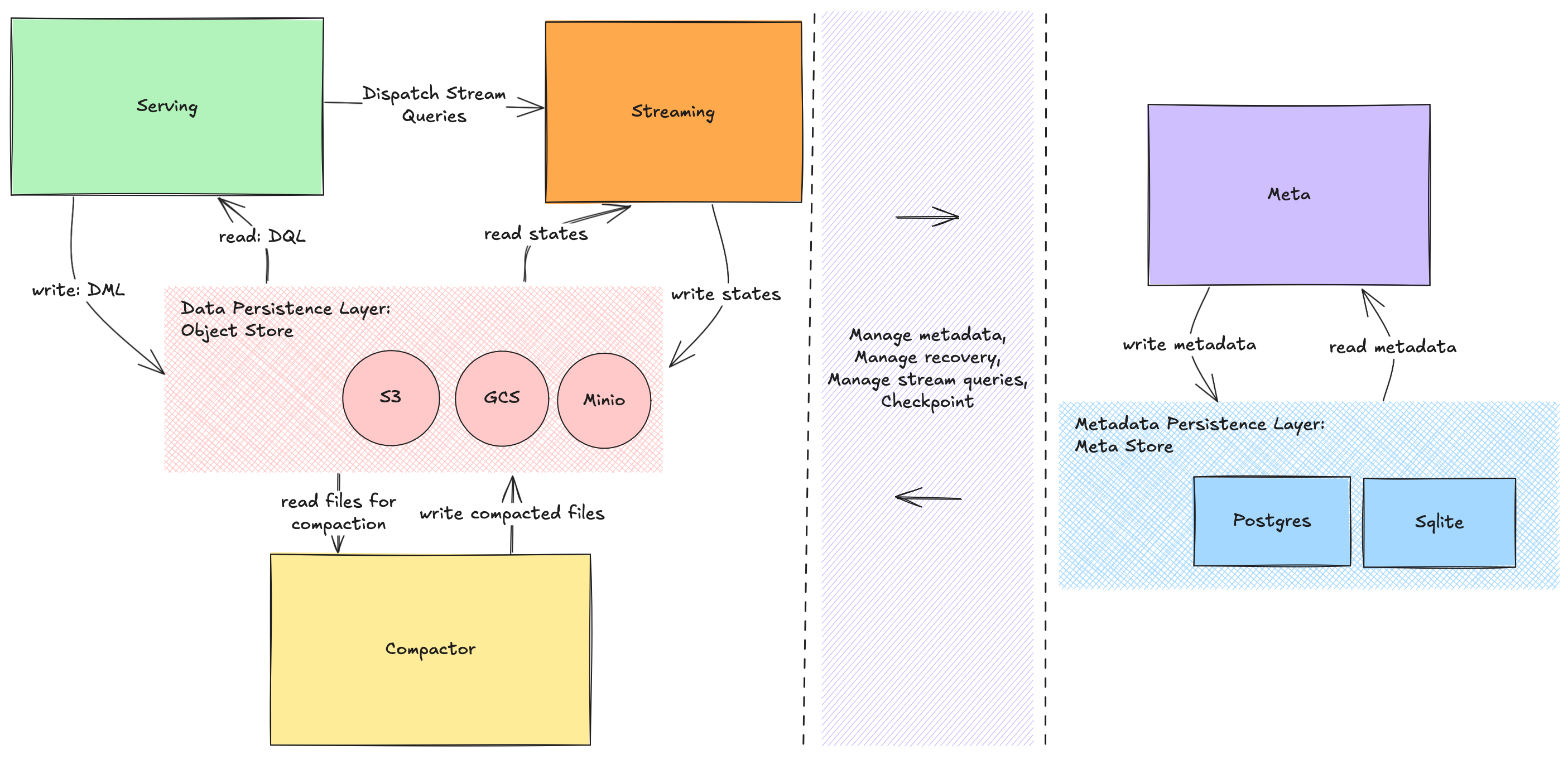
| Serving Node | The stateless node that parses and optimizes queries, and serves ad-hoc queries | It handles user connections, executes ad-hoc queries, and dispatches streaming jobs to the Streaming Nodes in a highly concurrent and low-latency manner. |
| Streaming Node | The core engine for stream processing | It executes the stream graph, maintains the state of streaming jobs, and performs continuous computations. |
| Meta Node | The central coordinator of the cluster | It manages metadata for all database objects and orchestrates the lifecycle of streaming jobs, including scheduling, checkpointing, and failure recovery. |
| Compactor Node | A background node that optimizes data storage | It performs compaction on the LSM-tree-based storage to improve read performance and reclaim space. |
Serving Node
This node serves as the PostgreSQL-compatible frontend. It handles user requests and delivers results with high concurrency and low latency. Clients likepsql can connect to it seamlessly.
- It executes batch queries directly.
- For streaming queries, it creates an execution plan and sends it to the Streaming Engine.
Batch query execution modes
There are two serving execution modes, local and distributed. Depending on the projected computational workload of the batch query, the system automatically selects one of these modes.- For queries that don’t require extensive computation, the primary overhead is likely in the initial optimization phases. In such cases, we use local execution mode. This mode avoids full optimizer passes and opts for simpler, heuristic-based passes. Point queries typically use this execution mode.
- For more complex queries with several joins and aggregations, we use distributed execution mode. These queries often require more time during batch execution; therefore, we thoroughly optimize them and distribute their execution across the Serving worker nodes.
The iceberg serving engine operates when a table is specified with
engine=iceberg, powered by Apache Iceberg table format. Data is stored in a columnar structure to enhance performance for ad hoc OLAP-style queries.Batch query lifecycle

Streaming Node
The Streaming Node executes streaming queries. This involves managing their state and performing computations such as aggregations and joins.Streaming query
These are queries that run incremental, “real-time” computation. Given a normal batch query like:CREATE MATERIALIZED VIEW, it can be changed to its streaming equivalent:
t receives a DML update like INSERT INTO t VALUES(1), this update propagates to m1. The stream graph for m1 takes the last count, adds 1 to it, and materializes this new count. You can query the latest results from m1 at any time using SELECT * FROM m1.
Streaming query lifecycle
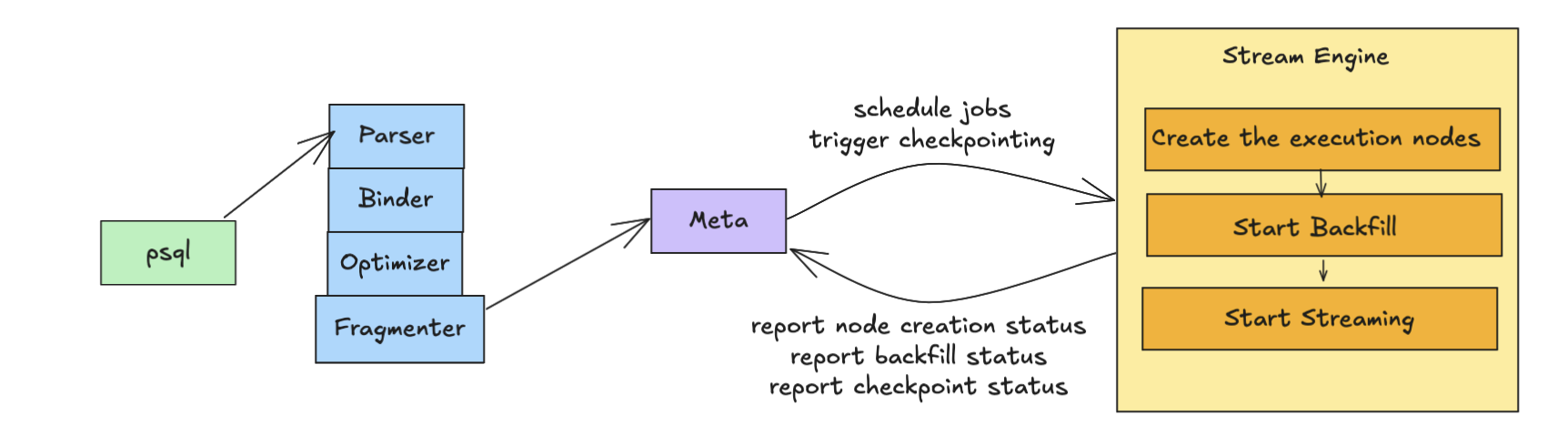
EXPLAIN to see what the execution graph looks like.
Once the execution nodes are built, we trigger historical data backfilling to ensure consistency with upstream sources. After backfilling completes, the streaming job will be created to continuously process upstream data, materialize updates, and propagate the transformed data stream to any downstream systems. See An overview of the RisingWave streaming engine for more information.
Meta Node
The Meta Node manages cluster metadata by interacting with a meta store, which serves as the persistence layer for metadata. RisingWave supports Postgres, MySQL, and SQLite as meta store options. All database objects are persisted in the meta store, while the Serving Node retrieves the database catalog from the Meta Node and caches it locally to serve queries. Additionally, the Meta Node manages the lifecycle of streaming jobs, including their creation, state checkpointing for consistency, and eventual deletion.- For job creation: The Serving Node sends the planned query to the Meta Node. The Meta Node then instantiates the query into actors and assigns them to Compute Nodes. It then triggers actor creation on the designated Compute Nodes.
- For checkpointing: The Meta Node sends barriers to the Streaming Nodes. These nodes commit their state and propagate the barriers downstream. Terminal nodes then return the barriers to the Meta Node for collection. Once all checkpoint barriers are collected and the state is uploaded to the object store, the checkpoint process completes, resulting in a consistent snapshot.
- For recovery and compaction: the Meta Node recreates actors on the Streaming Node, starting from the last checkpoint snapshot to maintain consistency. The Meta Node manages compaction by generating compaction tasks, assigning them to Compactor Nodes, and updating the meta store’s metadata upon task completion.
New to barriers and checkpoints? A barrier is a periodic sync marker; a checkpoint is a global consistent snapshot created from barriers. By default, RisingWave generates one barrier every 1 second (
barrier_interval_ms = 1000). See Data persistence.