CPU bottleneck
If you suspect that insufficient CPU resources are causing high latency, examine the following metrics and consider the recommended actions. In your Grafana dashboard (dev), navigate to Cluster Node > Node CPU panel, and locate the cpu usage (avg per core) - compute metric: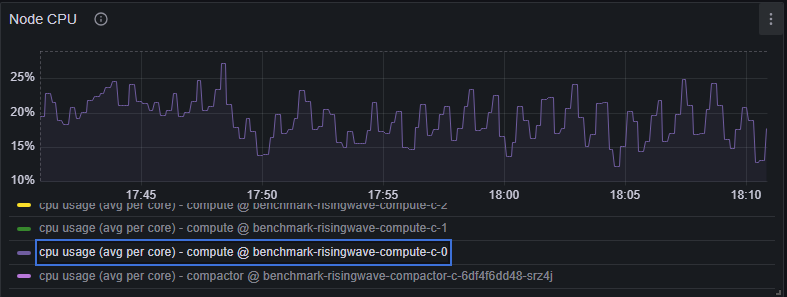
- CPU usage (avg per core) consistently exceeds 80%. See Resource utilization.
- Consider scaling up (adding more cores to a Streaming Node) or scaling out (adding more Streaming Nodes to the cluster). See Resource allocation.
- Low CPU usage doesn’t necessarily mean you can scale down. If the bottleneck is caused by slow state reads/updates due to insufficient memory, shrinking Compute Nodes might worsen the situation.
- High memory usage is expected in RisingWave, as it utilizes available memory for caching. For details, see Why is the memory usage so high?.
State access bottleneck (read)
Slow state access can significantly impact performance. This section helps you diagnose issues related to reading state data from the executor cache, storage, and storage cache. If you suspect issues with state access, start by checking Cache performance.Executor cache
In your Grafana dashboard (dev), navigate to Streaming Actors > Executor Cache Memory Usage panel.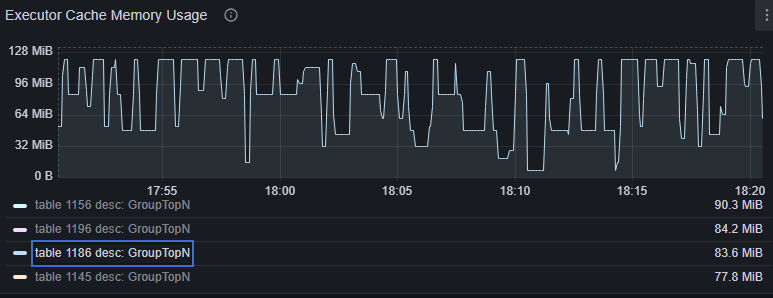
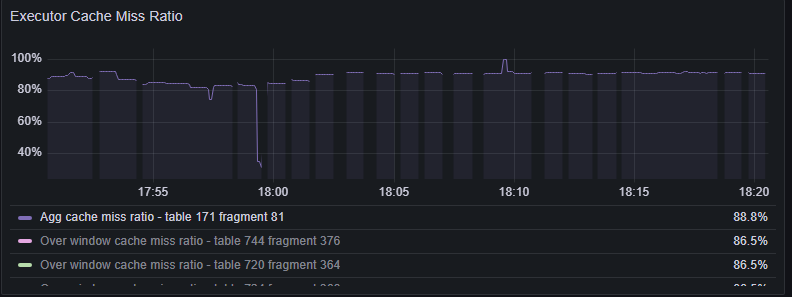
- Executor memory usage is significantly smaller than expected for the workload.
- High executor cache miss ratio.
- Increase Streaming Node memory by scaling up or scaling out. See Resource allocation.
Storage read
You can use the Grafana dashboard (dev) > Actor/Table Id Info > State Table Info to check the table name, table type, and the associated materialized view and fragment ID of a state table. You can infer the executor type by looking at thetable_name.
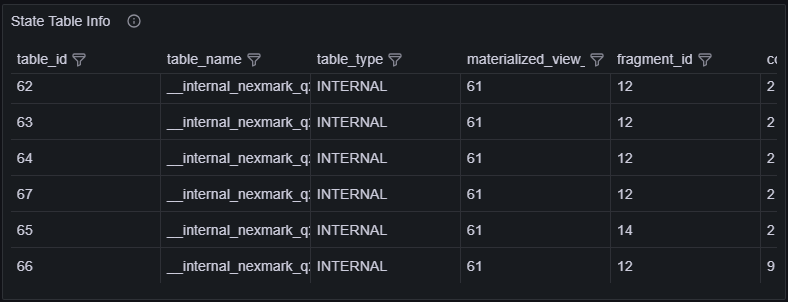
table_id(s) shown in the storage metrics.
Example:

Get: Used for point lookups (e.g., byHashAggexecutors).Iter: Used for range/prefix scans (e.g., byHashJoinexecutors).
Get operations
Navigate to Grafana dashboard (dev) > Hummock (Read) > Read Duration (Get)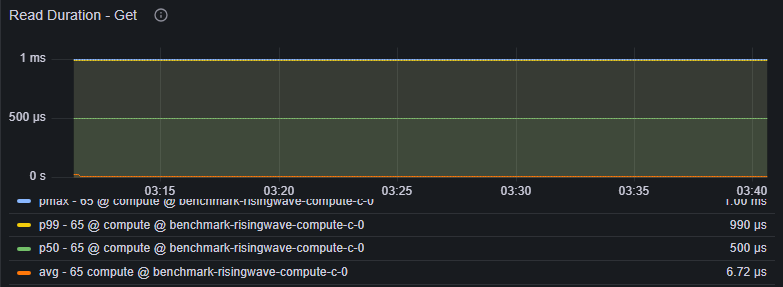
Get durations for each state table.
Indicators:
avg/p99duration consistently 10-100ms or higher.
- Investigate potential storage cache issues (see below).
Iter operations
Navigate to Grafana dashboard (dev) > Hummock (Read) > Read Duration (Iter)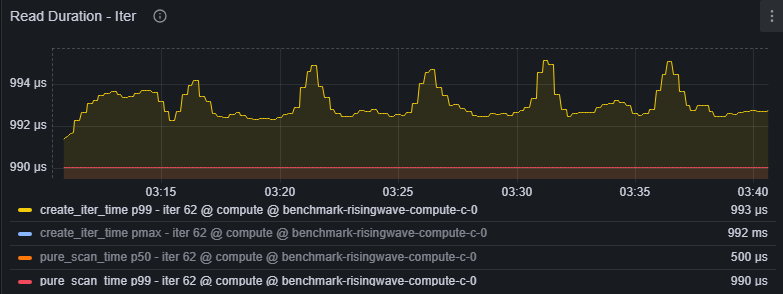
Iter durations, divided into:
create_iter_time: Time to initialize the storage iterator (fetching metadata, pruning files, initial seek).pure_scan_time: Time spent scanning data within the iterator.
p99duration consistently 10-100ms or higher.
- Check for excessive tombstones or stale keys (see below).
- Investigate potential storage cache issues (see below).
Tombstones and stale keys
Navigate to Grafana dashboard (dev) > Hummock (Read) > Iter Keys flow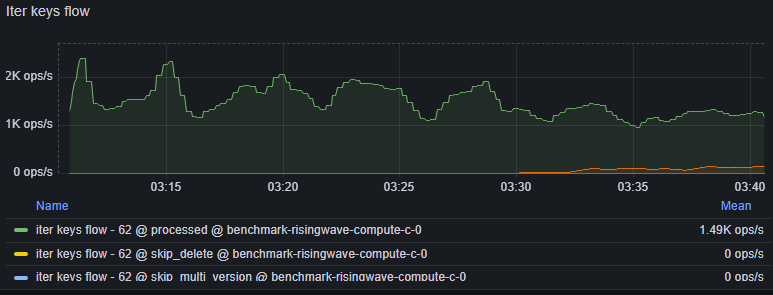
processed: Visible keys processed.skip_delete: Tombstone keys encountered (marked for deletion).skip_multi_version: Stale keys encountered (older versions of data).
- High
skip_deleteandskip_multi_versionvalues indicate that the compaction process is lagging.
- Investigate potential Compaction bottleneck.
Storage cache
RisingWave’s storage engine (Hummock) uses two types of cache:- Block cache (data cache): Caches blocks of data from stored files (SSTs). Each block is typically 64KB.
- Meta cache: Caches metadata about stored files (SSTs).
Block cache
Navigate to Grafana dashboard (dev) > Hummock (Read) > Cache Size.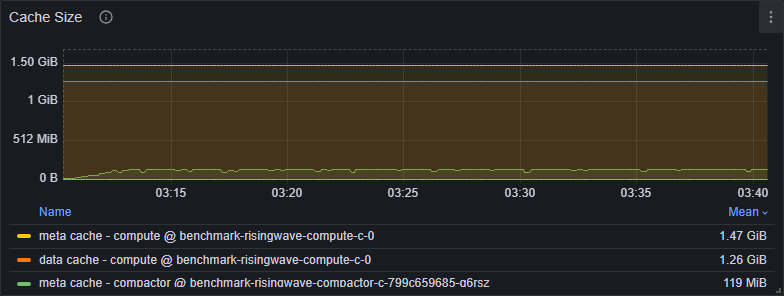
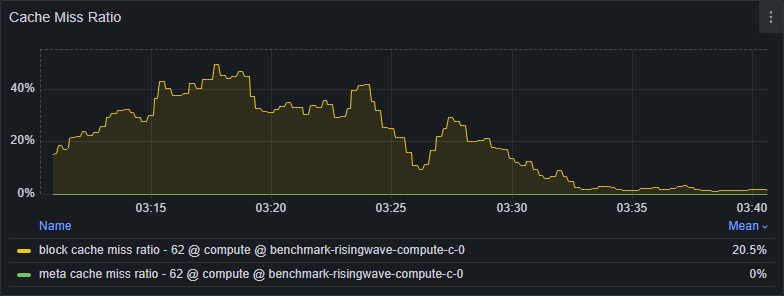
- High block cache miss ratio. This is influenced by both executor state access locality (better locality = lower miss ratio) and block cache capacity (smaller capacity relative to the working set = higher miss ratio).
- Scale up the Streaming Node or tune memory configurations. See Resource allocation.
- A high miss ratio alone doesn’t always indicate a problem. Consider the absolute number of misses. A low miss ratio with a very high number of total operations can still result in significant latency.
Meta cache
Navigate to Grafana dashboard (dev) > Hummock (Read) > Cache Ops.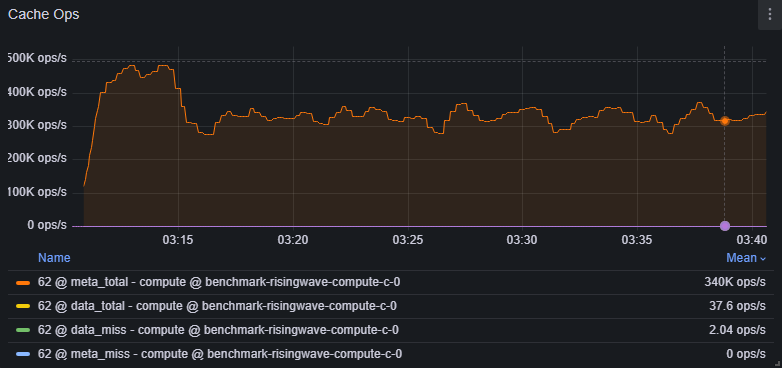
meta_miss: Should ideally be close to 0%.data_miss: Represents misses that require access to the remote object store.
meta_missis non-zero.data_missis high.
- Scale up the Streaming Node or tune memory configurations.
- Investigate potential Object store issues.
State update bottleneck (write)
If state updates are slow, executors may be blocked while waiting for space in the storage write buffer (also known as the shared buffer). Indicators: There are two ways to check whether the state update is backpressured by a full shared buffer:- Search for
blocked at requiring memoryin CN logs. If it shows up, some state table writes are waiting for the shared buffer quota to be released. - Check the “uploading memory - compute” metric (Grafana dashboard (dev) > Hummock (Write) > Uploader Memory Size). The shared buffer capacity is by default configured to be 4GB at max. If you see this time series consistently at or near the maximum, the shared buffer is likely full.
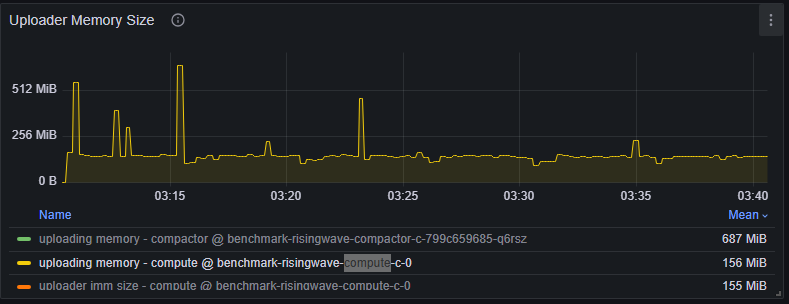
Slow object store writes
The shared buffer can only be released after in-memory state updates are flushed to the persistent remote object store. Navigate to Grafana dashboard (dev) > Streaming > Barrier sync latency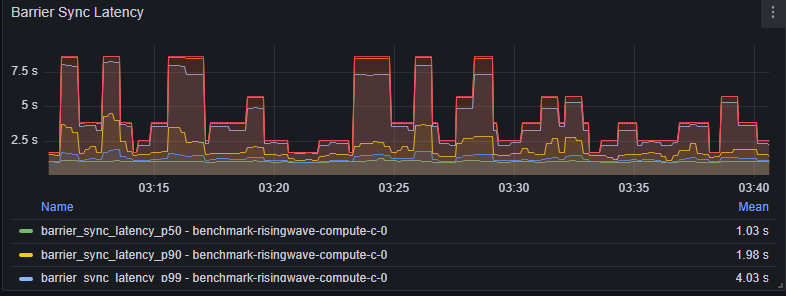
- Barrier sync latency takes up most of the barrier latency.
- Investigate potential Object store issues.
- High barrier sync latency doesn’t always mean slow object store writes. An overwhelmed storage event handler can also cause this.
Overwhelmed storage event handler
Storage uses an event loop to propagate storage events. If events pile up, state uploads can be delayed. Navigate to Grafana dashboard (dev) > Hummock (Write) > Event handler pending event number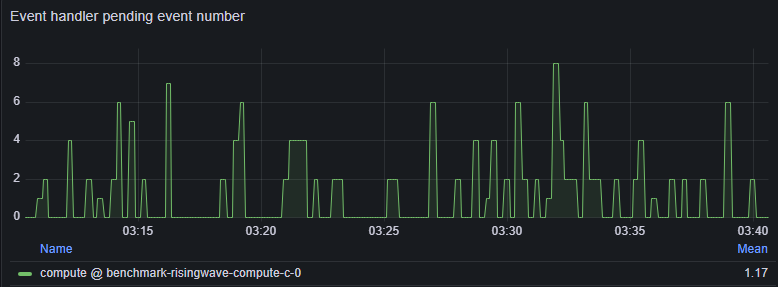
- The event number remains consistently high. This often indicates too many actors/state tables on a single Streaming Node.
- Check the per-compute-node actor count: Grafana dashboard (dev) > Actor/Table Id Info > Actor Count (Group By Compute Node)
- Add more Compute Nodes and rebalance actors.
Compaction bottleneck
Compaction merges and reorganizes data in storage, improving query performance and reclaiming space. Compaction bottlenecks can manifest in two main ways:Write stall
Indicators:-
Rows returned by this SQL query:
-
Data points shown in Grafana dashboard (dev) > Hummock Manager > Write Stop Compaction Groups.
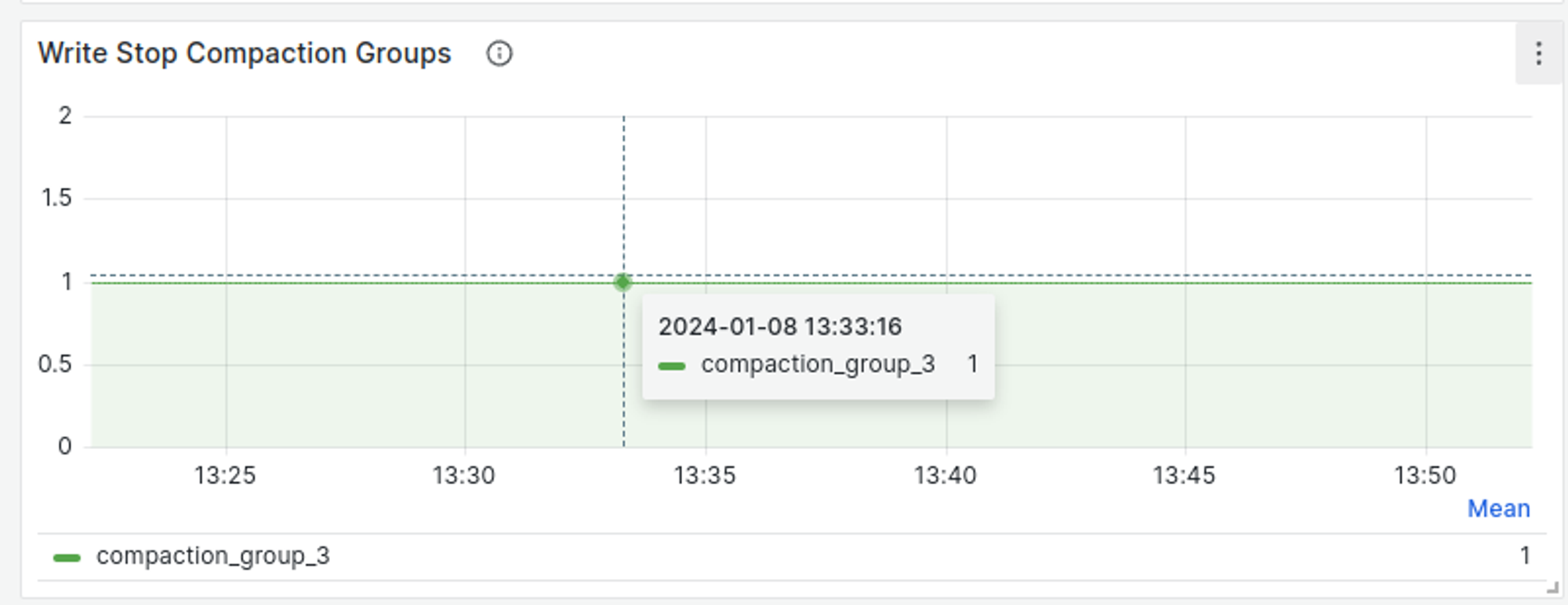
-
Compactor CPU is fully utilized: Grafana dashboard (dev) > Cluster Node > Node CPU panel, find the “cpu usage (avg per core) - compactor”
- Await Tree is stuck during the flush (visible in the Await Tree Dump).
- Scale up/out compactors. A recommended ratio is CN cores : compactor cores = 2 : 1.
- Investigate potential Object store issues.
- If scaling doesn’t resolve the issue, collect compactor logs, snapshots of the “Object Store” and “Compaction” panels in the Grafana dev dashboard, and the results of these SQL queries for further investigation:
- Compactors are primarily CPU-bound, so you can allocate less memory if needed (e.g., 4C 4GB is acceptable).
Too many tombstones or stale keys
Navigate to Grafana dashboard (dev) > Hummock Manager > Epoch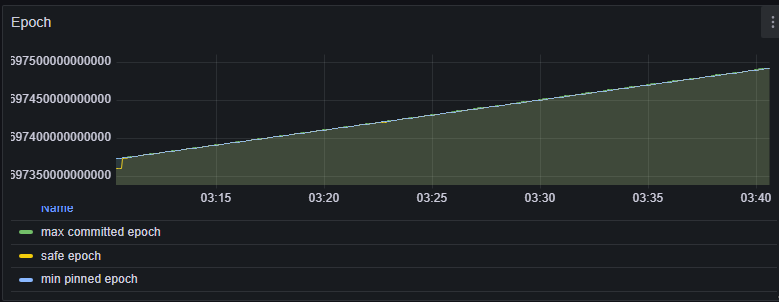
safe_epoch and max_committed_epoch is readable in a multi-version concurrency control (MVCC) manner. Compaction cannot reclaim data written above min_pinned_epoch.
Indicators:
- A large gap between
safe_epoch/min_pinned_epochandmax_committed_epoch.
- Check for long-running batch queries:
SHOW PROCESSLIST; - Trigger a manual recovery:
RECOVER; - Restart all serving nodes.
UDF bottleneck
Slow User-Defined Function (UDF) calls can significantly impact performance, as UDF invocation is in the critical path of streaming computation. Navigate to Grafana dashboard (dev) > User Defined Function section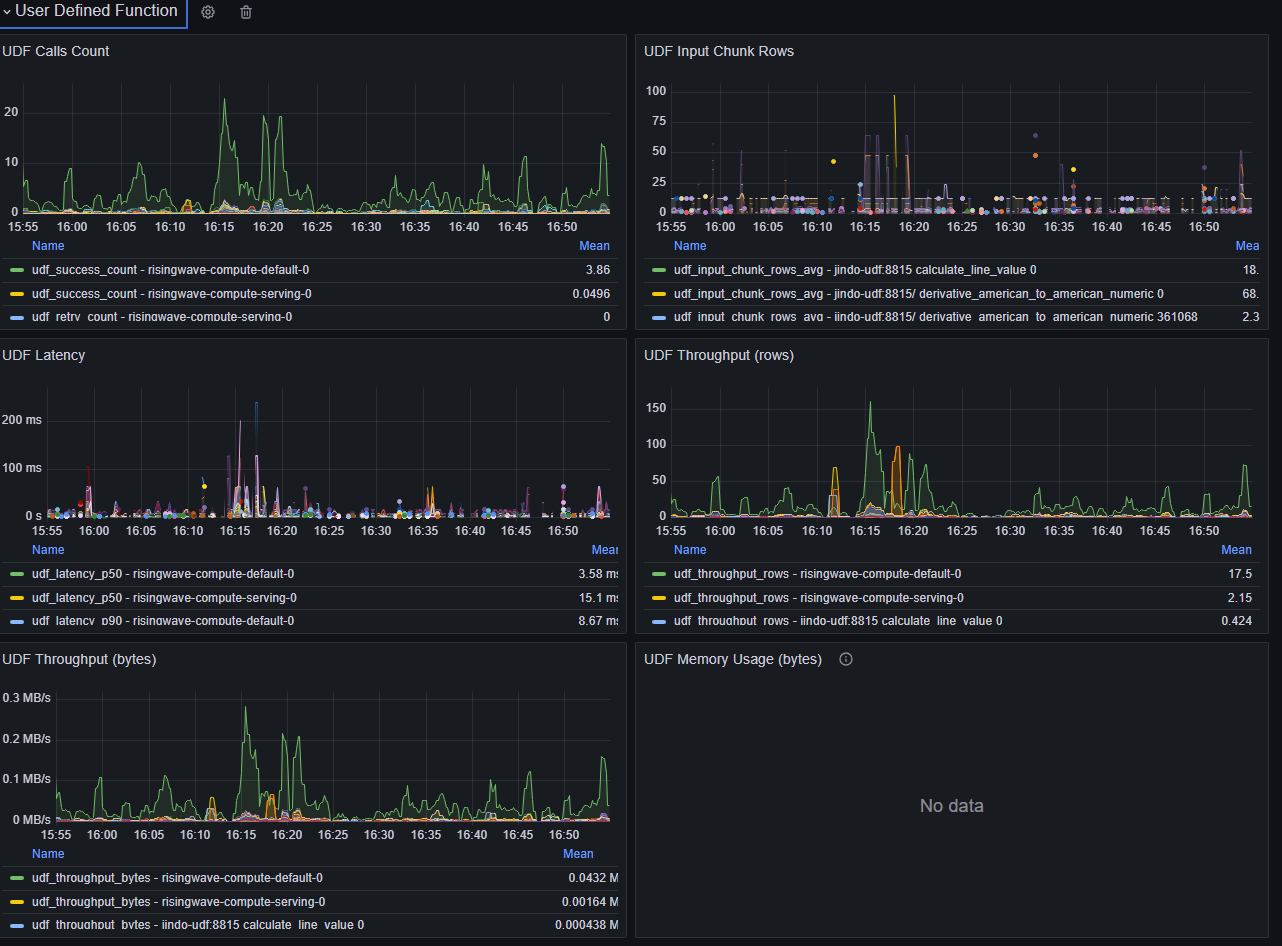
- Consistently high UDF latency.
- Check for network calls or I/O within the UDF.
- If using a UDF server, verify good network connectivity between RisingWave and the server.
Object store issues
Navigate to Grafana dashboard (dev) > Object Store > Operation Rate/Duration/Failure Rate/Retry Rate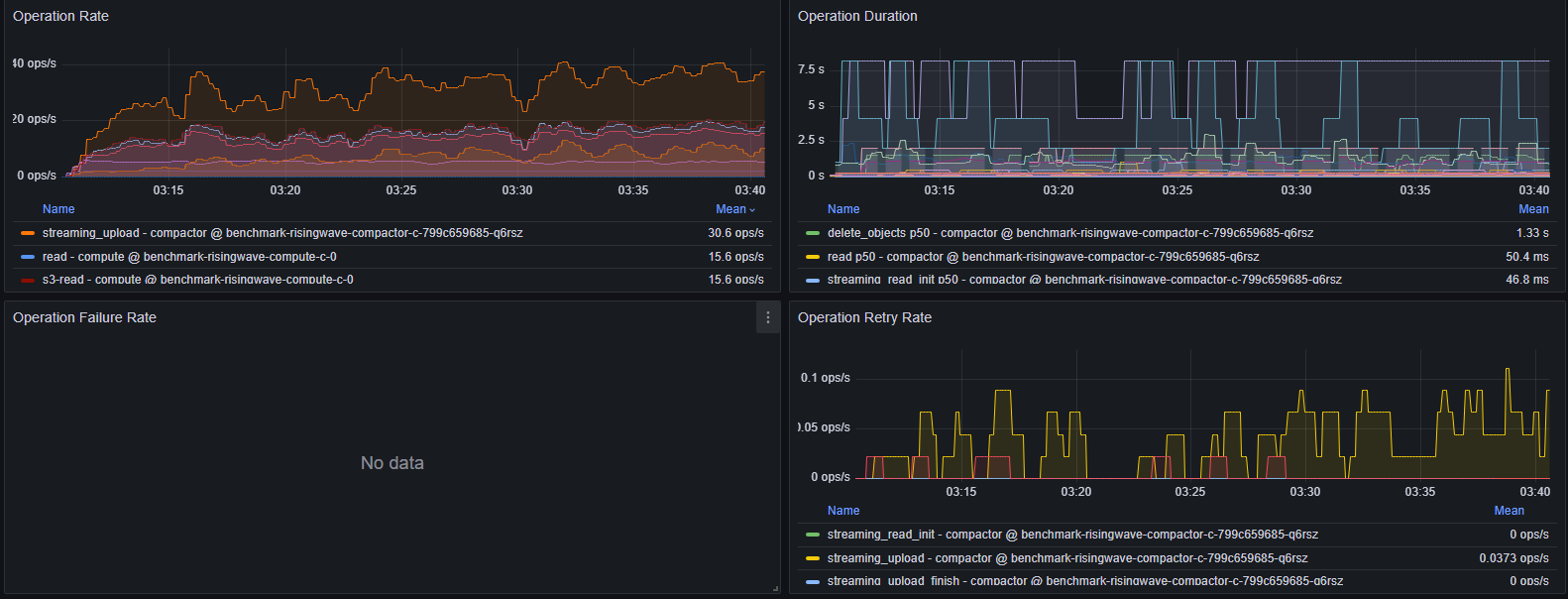
- High Operation Duration: Check logs for errors/warnings.
- High Operation Rate: With S3, >3000 OPS may cause duration spikes. Consider scaling up Compute Nodes to reduce cache misses.
- Persistent Operation Failure Rate: Indicates misconfiguration or network/object store unavailability. Check logs.
- Persistent Operation Retry Rate: Indicates misconfiguration or network/object store unavailability. Check logs. If retries are due to timeouts, consider tuning retry configurations.
Sink issues
Navigate to Grafana dashboard (dev) > User Streaming Errors > Sink Errors By Type
-
Sink decoupling isolates the sink but doesn’t improve its throughput. If the log store lag increases after enabling decoupling, investigate the sink itself:
Navigate to Grafana dashboard (dev) > Sink Metrics > Log Store Lag