CREATE MATERIALIZED VIEW for incremental computation that automatically updates as new data arrives, or run ad-hoc SELECT queries for on-demand batch analysis. Both modes use the same SQL syntax — no need to learn a separate streaming API or DSL.
Declare data processing logic in SQL
RisingWave uses PostgreSQL-compatible SQL as the interface for declaring data processing logic. This design provides two key benefits: Easy to use: By aligning with PostgreSQL’s syntax, functions, and data types, RisingWave minimizes the learning curve. Even for creating streaming jobs, there is no need to learn streaming-specific concepts — just write standard SQL. Powerful: RisingWave fully supports advanced SQL features including OVER window functions, multi-way JOINs (inner, outer, cross), time-windowed aggregations (tumble, hop, session), and semi-structured data types (JSONB, arrays, structs).Ad hoc (on read) vs. Streaming (on write)
There are 2 execution modes in our system serving different analytics purposes. The results of these two modes are the same and the difference lies in the timing of data processing, whether it occurs at the time of data ingestion(on write) or when the query is executed(on read).Understanding execution modes
Streaming: RisingWave allows users to predefine SQL queries with CREATE MATERIALIZED VIEW statement. RisingWave continuously listens changes in upstream tables (in theFROM clause) and incrementally update the results automatically.
Ad-hoc: Also like traditional databases, RisingWave allows users to send SELECT statement to query the result. At this point, RisingWave reads the data from the current snapshot, processes it, and returns the results.
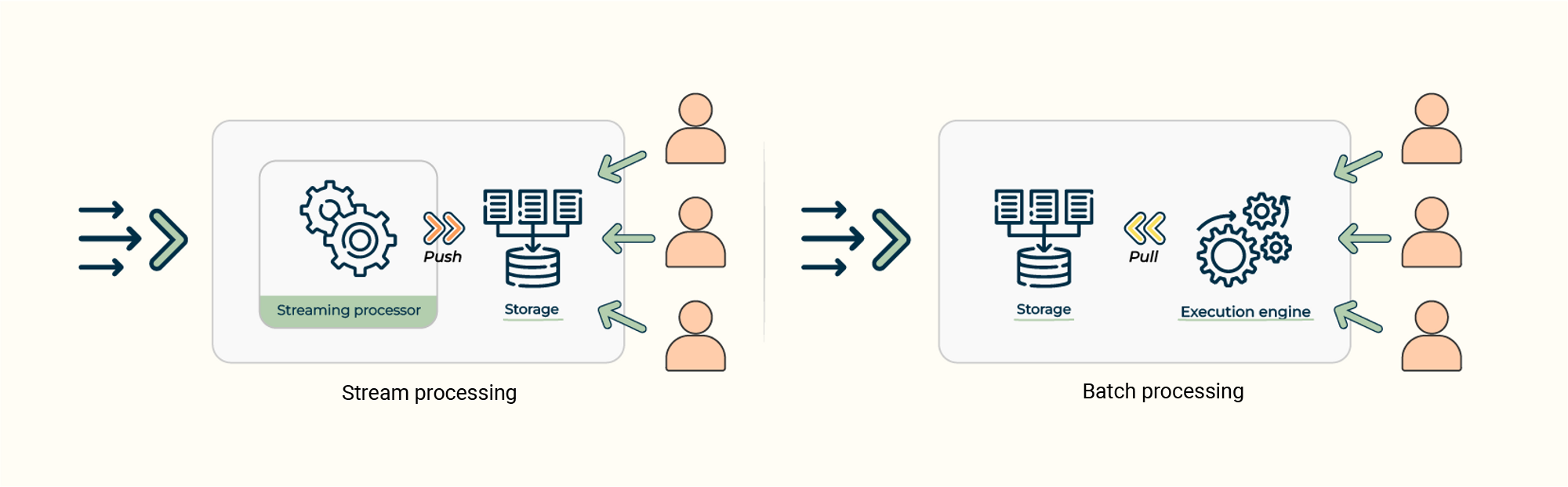
Query execution modes
When executing ad-hoc batch queries withSELECT, you can control the execution mode using the QUERY_MODE session variable:
distributed(default): Distributes query execution across multiple compute nodes for better parallelism. Use this for complex queries over large datasets.local: Executes the query on a single node. Use this for simple queries or when network overhead is a concern.auto: Lets RisingWave choose the appropriate mode based on query characteristics.
Examples
Create a table
To illustrate, let’s consider a hypothetical scenario where we have a table calledsales_data. This table stores information about product IDs (product_id) and their corresponding sales amounts (sales_amount).
table of sales_data
Create a materialized view to build continuous streaming pipeline
Based on thesales_data table, we can create a materialized view called mv_sales_summary to calculate the total sales amount for each product.
sales_data table into a materialized view called mv_sales_summary. This materialized view provides the total sales amount for each product. Utilizing materialized views allows for precomputing and storing aggregated data, which in turn improves query performance and simplifies data analysis tasks.
Ad-hoc query on materialized view’s result
Then we can directly query the materialized view to retrieve the transformed data:See also
- What is a Materialized View? — How incremental maintenance and cascading views work
- Data ingestion — How data enters RisingWave before processing
- Data delivery — How to send processed results to downstream systems
- CREATE MATERIALIZED VIEW — SQL reference