Merge multiple sinks with the same primary key
ON CONFLICT only controls how INSERT and UPDATE events are handled. By default, CREATE SINK ... INTO forwards DELETE events as well. If any upstream deletes a row with a given primary key, the corresponding row in the wide table will be deleted.To prevent DELETE events from removing rows in the wide table, force the sink to be append-only:type = 'append-only' and force_append_only = 'true' for this pattern.Enrich data with foreign keys in Star/Snowflake schema model
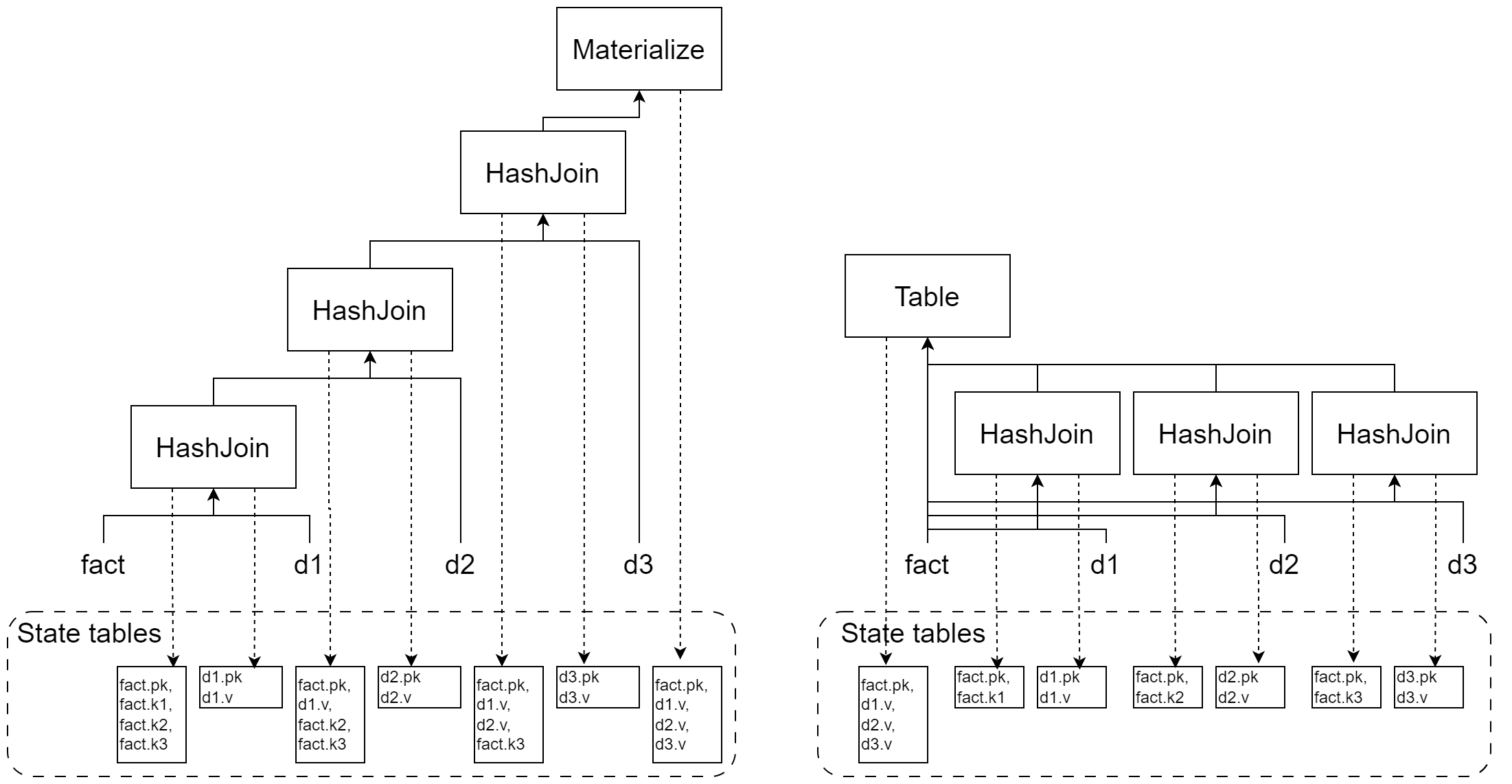
With star schema, the data is constructed with a central fact table surrounded by several related dimension tables. Each dimension table is joined to the fact table through a foreign key relationship. Given that the join key is the primary key of the dimension tables, we can rewrite the query as a series of sink into table.