The problem
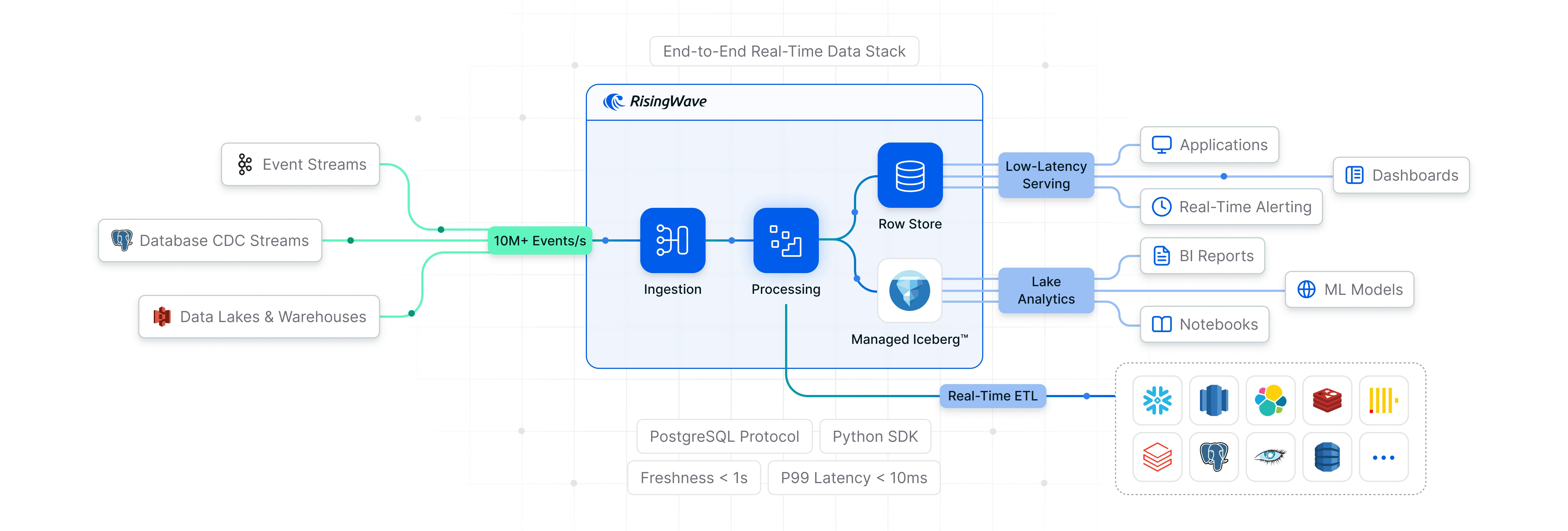
Real-time applications need data that is always fresh and queryable at low latency. The standard approach chains together Debezium for CDC, Kafka for transport, Flink for processing, and a database for serving. Each hop adds latency and each system adds operational overhead. RisingWave replaces the whole stack: ingest, process, serve, store.How it works
Ingest from any source
RisingWave ingests across the full data spectrum:- Webhooks: HTTP-based event ingestion from SaaS applications and external systems
- Database changes: Native CDC from PostgreSQL, MySQL, and others via transaction log reading
- Event streams: Kafka, Pulsar, Kinesis, and other message brokers
- Historical data: Batch ingestion from S3, data warehouses, and other storage systems
Process continuously
RisingWave performs incremental computation over ingested data. When upstream data changes, only the affected results are recomputed. End-to-end freshness is under 100 ms. This is the core mechanism: materialized views that are always up to date without full recomputation on every query.Serve at low latency
Query results are maintained in RisingWave’s internal row store and served at 10–20 ms p99 latency via standard SQL. No polling, no cache warming, no TTL management.Store in Apache Iceberg™
For long-term retention and analytical access, RisingWave writes to Apache Iceberg™ tables. It hosts the Iceberg REST catalog directly and handles table maintenance — compaction, small-file optimization, snapshot cleanup — without external tooling. Iceberg queries run via Apache DataFusion, a vectorized query engine. Because Iceberg is an open format, data is also readable by Spark, Trino, DuckDB, and other engines.Use cases
- Live dashboards: Materialized views updated incrementally as events arrive — no scheduled refreshes, no stale snapshots
- Monitoring and alerting: Continuous evaluation of streaming metrics against thresholds, with sub-second latency from event to alert
- Feature stores: Batch and streaming features computed over the same event pipeline, served from the same system at low latency
- Real-time enrichment: Live events joined with historical reference data in-flight, before delivery downstream
- Streaming lakehouses: Continuous, exactly-once ingestion into open-format tables with automated compaction and snapshot management
Design decisions
Ultimate cost efficiency
Internal state, tables, and materialized views are stored in object storage (S3 or equivalent) — roughly 100x cheaper than RAM. This enables elastic scaling without data rebalancing and failure recovery in seconds. For latency-sensitive workloads, elastic disk cache pins hot data on local SSD or EBS, keeping p99 query latency at 10–20 ms.Standard SQL interface
RisingWave connects via the PostgreSQL wire protocol and works with psql, JDBC, and any Postgres-compatible tooling. An MCP server is also available for programmatic access.Openness
RisingWave natively integrates with Apache Iceberg™ for continuous stream ingestion, direct reads via DataFusion, and automated table maintenance. Data in Iceberg is open format and accessible to any compatible query engine.See also
- Quick start — Install RisingWave and run your first streaming query
- Use cases — Detailed examples for each use case
- Recipes — Copy-paste implementation patterns
- Source, Table, MV, and Sink — The four core objects
- Data ingestion — Connect to Kafka, databases, and more
- Deployment options — Docker, Kubernetes, or Cloud