CREATE TABLE to properly handle updates and deletes. For more details about the differences between sources and tables, see here.
Regardless of whether the data is persisted in RisingWave, you can create materialized views to perform analysis or data transformations.
Syntax
Notes
A generated column is defined with non-deterministic functions. When the data is ingested, the function will be evaluated to generate the value of this field. Names and unquoted identifiers are case-insensitive. Therefore, you must double-quote any of these fields for them to be case-sensitive. See also Identifiers. To know when a data record is loaded to RisingWave, you can define a column that is generated based on the processing time (<column_name> timestamptz AS proctime()) when creating the table or source. See also proctime().
For a source with schema from an external connector, use * to represent all columns from the external connector first, so that you can define a generated column on the source with an external connector. See the example below.
The generated column is created in RisingWave and will not be accessed through the external connector. Therefore, if the external upstream system has a schema, it does not need to include the generated column within the table’s schema in the external system.
Parameter
| Parameter | Description |
|---|---|
| source_name | The name of the source. If a schema name is given (for example, CREATE SOURCE <schema>.<source> …), then the table is created in the specified schema. Otherwise it is created in the current schema. |
| col_name | The name of a column. |
| data_type | The data type of a column. With the struct data type, you can create a nested table. Elements in a nested table need to be enclosed with angle brackets (<>). |
| generation_expression | The expression for the generated column. For details about generated columns, see Generated columns. |
| watermark_clause | A clause that defines the watermark for a timestamp column. The syntax is WATERMARK FOR column_name as expr. For details about watermarks, refer to Watermarks. |
| INCLUDE clause | Extract fields not included in the payload as separate columns. For more details on its usage, see INCLUDE clause. |
| WITH clause | Specify the connector settings here if trying to store all the source data. See Supported sources for the full list of supported source as well as links to specific connector pages detailing the syntax for each source. |
| FORMAT and ENCODE options | Specify the data format and the encoding format of the source data. To learn about the supported data formats, see Data formats and encoding options. |
Please distinguish between the parameters set in the FORMAT and ENCODE options and those set in the WITH clause. Ensure that you place them correctly and avoid any misuse.
Connector-specific FORMAT requirements
Different connectors have specific FORMAT and ENCODE requirements:- For specialized connectors (CDC, Nexmark, Datagen, Iceberg), the FORMAT and ENCODE clauses are handled automatically and should be omitted.
- For other connectors** (Kafka, Kinesis, Pulsar, etc.), you need to explicitly specify FORMAT and ENCODE specification based on the actual data format.
NOT NULL constraints are not supported in source schemas. If you need NOT NULL enforcement, use
CREATE TABLE with a connector instead.Watermarks
RisingWave supports generating watermarks when creating a source. Watermarks are like markers or signals that track the progress of event time, allowing you to process events within their corresponding time windows. The WATERMARK clause should be used within theschema_definition. For more information on how to create a watermark, see Watermarks.
Upsert sources
You can create sources withFORMAT UPSERT to handle streams with updates and deletes based on a primary key. When using FORMAT UPSERT, you must:
- Include the
INCLUDE KEYclause to specify a key column - Define a
PRIMARY KEYusing the key column
Example
-
Simple ETL with filtering and transformation:
-
Materialize to enable stateful operations:
Upsert sources emit upsert streams, which do not contain old values for
UPDATE operations. Therefore, stateful operators like JOINs, aggregations, and window functions do not work on an upsert source. Attempting to do so will result in errors like "upsert stream is not supported as input of ...".Change Data Capture (CDC)
Change Data Capture (CDC) refers to the process of identifying and capturing data changes in a database, and then delivering the changes to a downstream service in real-time. RisingWave provides native MySQL and PostgreSQL CDC connectors. With these CDC connectors, you can ingest CDC data from these databases directly, without setting up additional services like Kafka. If Kafka is part of your technical stack, you can also use the Kafka connector in RisingWave to ingest CDC data in the form of Kafka topics from databases into RisingWave. You need to use a CDC tool such as the Debezium connector for MySQL to convert CDC data into Kafka topics. For complete step-to-step guides about ingesting MySQL and PostgreSQL data using both approaches, see Ingest data from MySQL and Ingest data from PostgreSQL.Shared source
Shared source improves resource utilization and data consistency when working with Kafka sources in RisingWave. This will only affect Kafka sources created after the version updated and will not affect any existing Kafka sources.Shared Kafka source is available since version 2.1. Other sources are unaffected. We plan to gradually upgrade other sources to the be shared as well in the future.
ALTER SOURCE [ADD COLUMN | REFRESH SCHEMA] for shared source is available since version 2.2.Configure
Shared source is enabled by default. You can also set the session variablestreaming_use_shared_source to control whether to enable it.
risingwave.toml configuration file, and set the stream_enable_shared_source to false.
Compared with non-shared source
With non-shared sources, when using theCREATE SOURCE statement:
- No streaming jobs would be instantiated. A source is just a set of metadata stored in the catalog.
- Only when a materialized view or sink references the source, a
SourceExecutorwill be created to start the process of data ingestion.
- Each
SourceExecutorconsumed Kafka resources independently, adding pressure to both the Kafka broker and RisingWave. - Independent
SourceExecutorinstances could result in different consumption progress, causing temporary inconsistencies when joining materialized views.
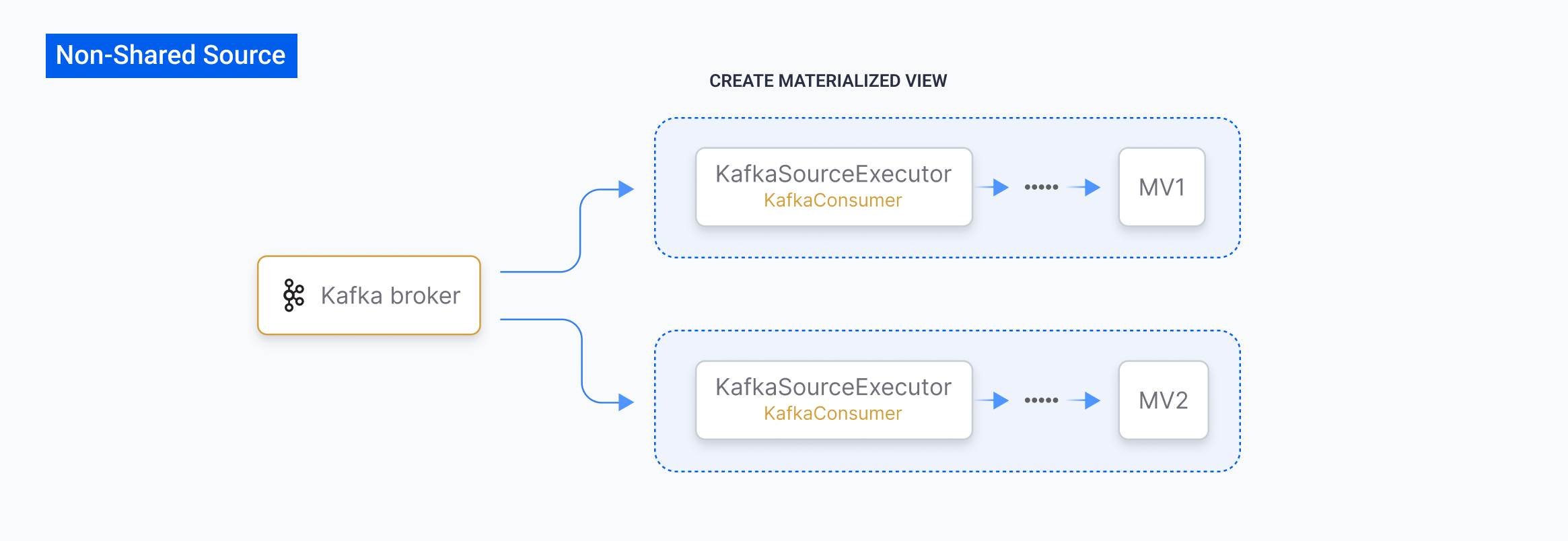
CREATE SOURCE statement:
- It will instantiate a single
SourceExecutorimmediately. - All materialized views referencing the same source share the
SourceExecutor, thus the same start offset and consumption progress. - The downstream materialized views will only forwards data from the upstream sources, instead of consuming from Kafka independently.
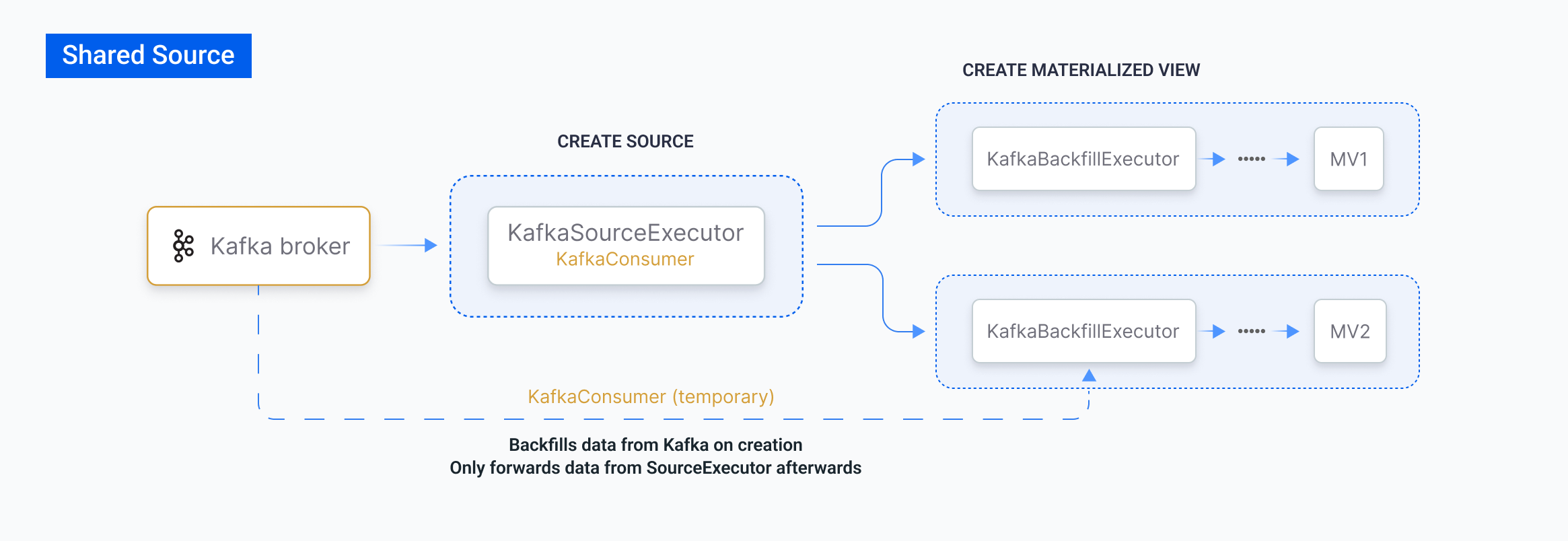
- To configure this behavior, use the SET BACKGROUND_DDL command. This is similar to the backfilling procedure when creating a materialized view on tables and materialized views.
-
To monitoring backfill progress, use the SHOW JOBS command or check
Kafka Consumer Lag Sizein the Grafana dashboard (underStreaming).
Even if a source is created with
scan.startup.mode set to latest, a materialized view may still backfill from the offset resolved at source creation time. To start from the current latest offset, drop and recreate the source.If you set up a retention policy or if the external system can only be accessed once (like message queues), and the data is no longer available, any newly created materialized views won’t be able to backfill the complete historical data. This can lead to inconsistencies with earlier materialized views.
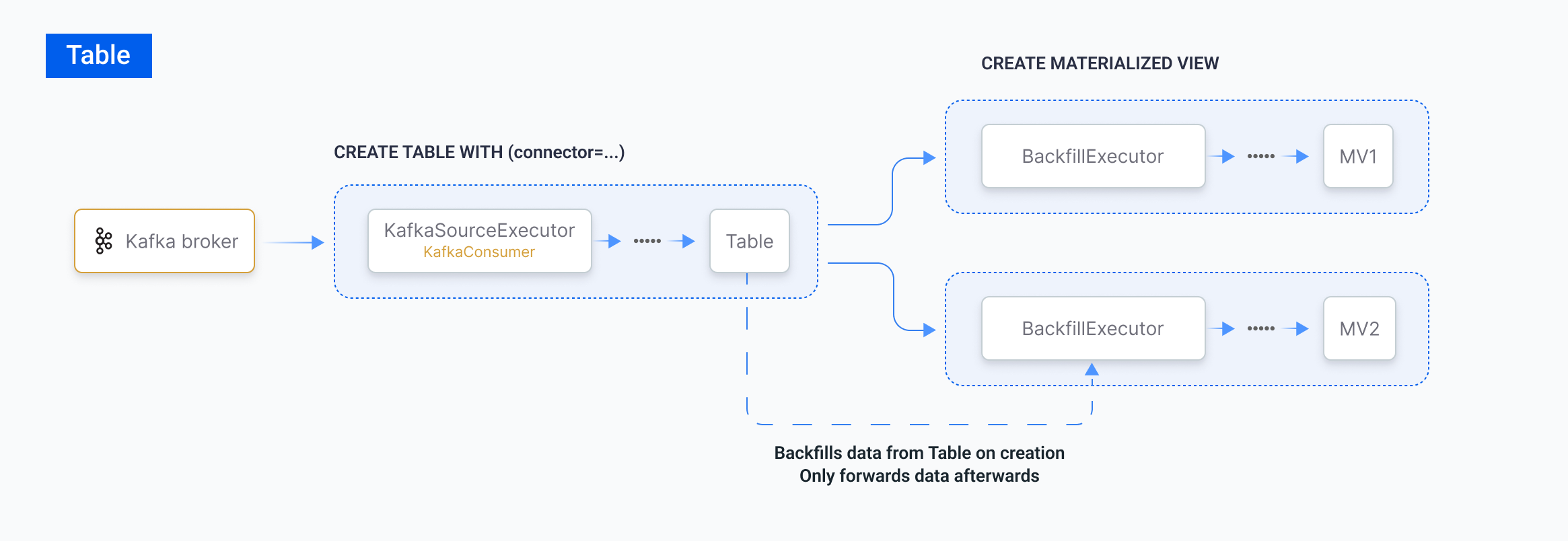
Compared with table
ACREATE TABLE statement can provide similar benefits to shared sources, except that it needs to persist all consumed data.
For table with connector, downstream materialized views backfill historical data from the table instead of external sources, which may be more efficient and cause less pressure to the external system. This also gives table stronger consistency guarantee, as historical data will be ensured to be present.
Tables offer other features that enhance their utility in data ingestion workflows. See Table with connectors.
See also
Overview of data ingestion
DROP SOURCE
Remove a source
SHOW CREATE SOURCE
Show the SQL statement used to create a source
ALTER SOURCE
Modify a source